Feat/OpenArm Demo Pick task + continuous-gripper staged grasp#640
Feat/OpenArm Demo Pick task + continuous-gripper staged grasp#640alexhegit wants to merge 3 commits into
Conversation
…tions Generic offline-play / video-export controls, wired through every training entry point's play path (rsl_rl, appo, him_ppo, mlx_ppo, offpolicy, hora): - play_hide_geom_groups: MuJoCo geom groups (0..5) to hide when rendering the offline play video (e.g. a workcell shell that occludes the arm). - play_video_fps: MP4 playback fps; null matches physics rate, lower values give slow-motion playback. - play_stochastic (rsl_rl): sample the policy stochastically during play/export so motion is visible when the action mean sits near zero. render_many gains _apply_hide_geom_groups + a hide_geom_groups arg; the MuJoCo playback helper gains the fps override and a libx264->mpeg4 codec fallback. Defaults preserve existing behavior (no hidden groups, physics fps, deterministic play). Co-authored-by: Cursor <cursoragent@cursor.com>
Add a single-arm OpenArm pick-and-place task (cube -> 3D goal) on the MuJoCo backend, with the continuous-gripper variant, staged grasp reward shaping, headless eval, and a scripted IK demo. Task & assets - openarm_demo_pick env (src/unilab/envs/manipulation/openarm/pick_place_demo.py) with the openarm_mujoco_v2 robot assets and scene/cell/pedestal XML. - Hydra configs under conf/ppo/task/openarm_demo_pick/: mujoco.yaml (binary-gripper base), mujoco_lift3d.yaml (3D in-air goal) + mujoco_lift3d_easy.yaml, and mujoco_lift3d_contgrip.yaml (continuous gripper, final staged + firm grasp shaping). Reward shaping (mujoco_lift3d_contgrip) - Staged grasp: approach (hover-above-open), premature_close penalty, action_rate smoothness -> goal-accurate pick 0% -> 87% 3D success. - Firm-grasp incentive: firm_grasp = closure x lift_gate x proximity, paid only once the cube is lifted and the TCP is on it. Best result across 5 seeds x 512 envs (2560 episodes): ever-success 100%, final-success 92.3% (90.8-93.4), drop rate 0%, mean goal dist ~0.02 m. The learned grasp is a stable open fingertip-cradle (closure ~0); for this geometry the open cradle is the robust optimum and forcing closure hurts the objective. Tooling - scripts/eval_openarm_success.py: headless success-rate eval with staged-grasp adherence + grasp-firmness metrics. - scripts/openarm_scripted_pick.py: scripted 6-DOF damped-LS IK pick demo; scripts/verify_openarm_play_motion.py: playback sanity check. Backend support - MuJoCo backend/xml: compile_model_with_tracking_sensors to handle <attach>-ed scenes (cell + bimanual + finger links) under MuJoCo >=3.8, where the MjSpec.to_xml() -> from_xml_path() round-trip corrupts nested defaults; resolve tracked-body ids against the compiled model. - np_env: after_physics_substeps hook for backend state adjustment. Validated with `make test-all` on a ROCm (AMD MI210) host: check (ruff/mypy/pyright) green; pytest 1258 passed, 15 skipped. The only failures are 2 CUDA-only ipc tests (pybind11 H2D submitter unavailable on ROCm); this change touches no ipc code. Co-authored-by: Cursor <cursoragent@cursor.com>
Re-validation after rebase onto latest
|
| metric | this run (rebased) | prior run |
|---|---|---|
| ever-success | 98.8% | 100% |
| final-success | 86.3% | 90.4% |
| drop rate | 0% | 0% |
| final 3D dist | 0.034 m | 0.025 m |
| grasp closure | 0.000 (open fingertip-cradle) | 0.001 |
→ rebase / 冲突解决未改变任务行为;86.3% vs 90.4% 属单 seed 的 run 方差。
Playback / video recording (deterministic, slow-motion MP4 → run dir play_video.mp4):
HIP_VISIBLE_DEVICES=0 uv run eval --algo ppo --task openarm_demo_pick --sim mujoco \
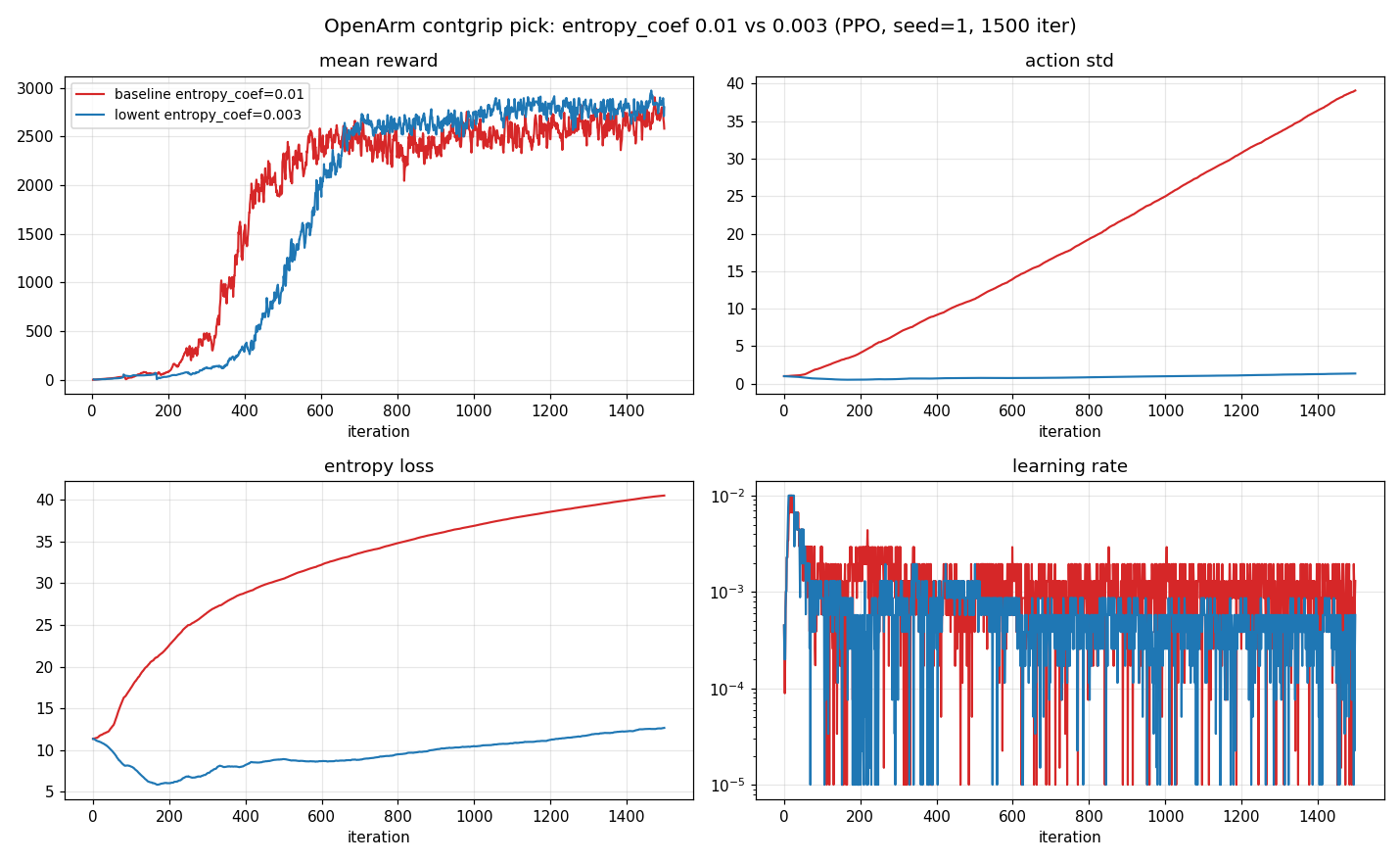
--profile lift3d_contgrip --load-run 2026-06-28_07-08-08_mujoco training.play_steps=300TensorBoard curve analysis:
| iter | reward | ep_len | action_std | entropy | value_loss |
|---|---|---|---|---|---|
| 0 | 1.9 | 85 | 1.0 | 11.4 | 0.009 |
| 200 | 80 | 1400 | 4.1 | 22.6 | 3.7 |
| 400 | 1540 | 1770 | 9.2 | 28.9 | 17.4 |
| 600 | 2420 | 1970 | 13.9 | 32.2 | 48.8 |
| 1000 | 2620 | 2000 | 25.0 | 36.9 | 39.9 |
| 1499 | 2580 | 2000 | 39.1 | 40.5 | 16.6 |
- 任务在 iter ~400–600 收敛(reward / episode-length 进入平台),1500 iter 有富余。
- reward 绝对值大(~2580)是
terminate_on_success=false× 2000-step episode 下稠密项累加所致;episode_length 顶满 2000 + drop 0% 证明策略学会稳定保持。 - surrogate loss 全程 ~0、value loss 先升后回落(峰值 ~49→16),PPO 优化健康。
- 唯一现象:action std 随训练单调升到 39(entropy 同步升)。这是 tanh 压缩动作 + 熵奖励的典型现象——任务解决后均值动作改进梯度趋零,而
entropy_coef=0.01持续奖励更大 std,且动作经 tanh 饱和使大 std 不影响实际执行。只影响随机探索;eval 用均值,成功率不受损,且与本 PR 改动无关。可选后续:entropy_coef降至 ~0.001–0.003、或max_iterations降到 ~600。
CI / docs: make test-all 1352 passed(2 个失败为 main 自身在无头环境的 rich 终端宽度问题,已用纯净 main worktree 复现,与本 PR 无关);docs test_check_docs 20 passed + sphinx-build -n 无 warning。
|
训练曲线 
|
训练参数调优:低熵 contgrip 变体(
|
| 指标 | baseline 0.01 |
lowent 0.003 |
|---|---|---|
| ever success(512-env 确定性 eval) | 98.8% | 100.0% |
| final success | 86.3% | 87.9% |
| drop rate | 0% | 0% |
| 最终 reward | 2580 | 2800 |
| 最大 reward | 2903 | 2971 |
最终 action std |
39.08 | 1.35 |
最终 entropy loss |
~40(单调爬升) | ~12(平稳) |
净改进:曲线干净(std/entropy 不再漂移),确定性成功率持平/略升,reward 略高。唯一代价是到平台约晚 ~150 iter(早期探索噪声更小)。端到端经 --profile lift3d_contgrip_lowent 复跑,结果与 CLI override 逐位一致。
学到的抓取是稳定的开指托举(fingertip-cradle,闭合度 ≈ 0),对该高摩擦小方块几何是更鲁棒的最优解:

复现命令
训练(无渲染):
uv run train --algo ppo --task openarm_demo_pick --sim mujoco \
--profile lift3d_contgrip_lowent training.no_play=true确定性评估(512 env,成功率/抓取指标):
HIP_VISIBLE_DEVICES=0 uv run scripts/eval_openarm_success.py \
task=openarm_demo_pick/mujoco_lift3d_contgrip_lowent \
algo.load_run=logs/rsl_rl_ppo/OpenArmDemoPick/<run>_mujoco \
+training.eval_envs=512 training.play_steps=200标准回放视频(写到 run 目录 play_video.mp4):
uv run eval --algo ppo --task openarm_demo_pick --sim mujoco \
--profile lift3d_contgrip_lowent --load-run -1夹爪闭合细节特写视频(单 env,左臂右前方低机位):
MUJOCO_GL=egl HIP_VISIBLE_DEVICES=0 uv run eval --algo ppo --task openarm_demo_pick \
--sim mujoco --profile lift3d_contgrip_lowent \
algo.load_run=logs/rsl_rl_ppo/OpenArmDemoPick/<run>_mujoco \
training.play_env_num=1 training.play_steps=260 training.play_video_fps=8 \
training.cam_distance=0.55 training.cam_elevation=-8.0 training.cam_azimuth=150.0 \
"training.cam_lookat=[0.46,0.0,1.04]"Validation
make test-all:ruff format/ruff check/mypy(223 源文件 no issues)/pyright(0 errors)全部通过;pytest1327 passed, 41 skipped。- 余下 2 个失败为 预存、与本改动无关 的环境问题:
tests/utils/test_experiment_tracking.py的两个 offpolicy 终端日志用例,在非 TTY 下 rich console 按固定宽度渲染表格、断言子串被框线/截断所致(本 PR 仅新增一个 YAML + 文档 + 两张图片,不触碰任何 Python 代码路径)。
Add `mujoco_lift3d_contgrip_lowent` owner variant: identical task/reward to `lift3d_contgrip` but lowers the PPO entropy bonus from 0.01 to 0.003. This removes the post-convergence `action std` / `entropy` drift (std 39 -> 1.35, entropy ~40 -> ~12) that PPO accrues for free under tanh saturation, yielding a cleaner training curve with equal/slightly-better deterministic success (ever 98.8% -> 100%, final 86.3% -> 87.9%, drop 0%). Document the variant + result comparison (curves + grasp close-up) in the zh/en OpenArm pick pages. Validation (PPO, seed=1, 4096 env x 24 steps x 1500 iter): - trained end-to-end via `--profile lift3d_contgrip_lowent`; eval 512 env. - make test-all: ruff/format/mypy/pyright pass, 1327 passed; 2 pre-existing offpolicy rich-console rendering failures (non-TTY width), unrelated. Co-authored-by: Cursor <cursoragent@cursor.com>
c0636f4 to
cc03a08
Compare
Summary
OpenArmDemoPick(
src/unilab/envs/manipulation/openarm/pick_place_demo.py)+openarm_mujoco_v2机器人资产与scene/cell/pedestal XML;4 个 Hydra owner 变体
mujoco/mujoco_lift3d/mujoco_lift3d_easy/mujoco_lift3d_contgrip(连续夹爪 + staged/firm grasp shaping)。mlx_ppo / offpolicy / hora)支持
play_hide_geom_groups(隐藏遮挡 geom 组)、play_video_fps(慢动作回放)、
play_stochastic(随机采样以显现动作)。默认行为不变。清晰的回放视频。
Linked Work
Validation
make test-all(包含make check的 ruff/mypy/pyright + pytest):1352 passed, 15 skipped。2 个失败
tests/utils/test_experiment_tracking.py::test_offpolicy_logger_terminal_*在纯净main上同样失败(用临时 worktree 验证),根因是无头环境 rich
Console()非 TTY 默认 80 列截断标签,与本 PR 无关——本 PR 未修改 offpolicy logger 源码。
pytest tests/scripts/test_check_docs.py20 passed;sphinx-build -n(nitpicky)buildsucceeded,无 warning(中英 OpenArm 任务页均生成)。
Commands actually run: