{kind=link}
{kind=link}
Overview
This project builds a machine learning model to detect fraudulent transactions in a highly imbalanced dataset.
The focus is on practical model performance — balancing fraud detection (recall) with minimising false alarms (precision), rather than maximising raw accuracy.
Key Results
- Precision: 0.74
- Recall: 0.57
- F1 Score: 0.65
- Alert Rate: 0.6%
This means:
- ~3 in 4 flagged transactions are genuine fraud
- ~57% of fraud cases are successfully detected
- Only 0.6% of all transactions are flagged for review
Problem Characteristics
Fraud detection is a highly imbalanced classification problem:
- Fraud cases are rare
- Standard accuracy is misleading
- False positives carry operational cost
Approach
-
Data Processing
- Removed non-informative identifier column
- Defined target variable (target_ml) as fraud (positive class)
- Train/test split performed before resampling
-
Handling Class Imbalance
- Applied undersampling, oversampling (SMOTE) and class weighting to training data only
- Prevented data leakage by keeping test data untouched
-
Classifiers Evaluated
- Random Forest Classifier
- Logistic Regreesion
- Support Vector
- Gradient Boosting (XGBoost)
-
Model Selection
- Models evaluated using:
- Precision
- Recall
- F1 Score
-
Threshold tuning used instead of default 0.5 cutoff
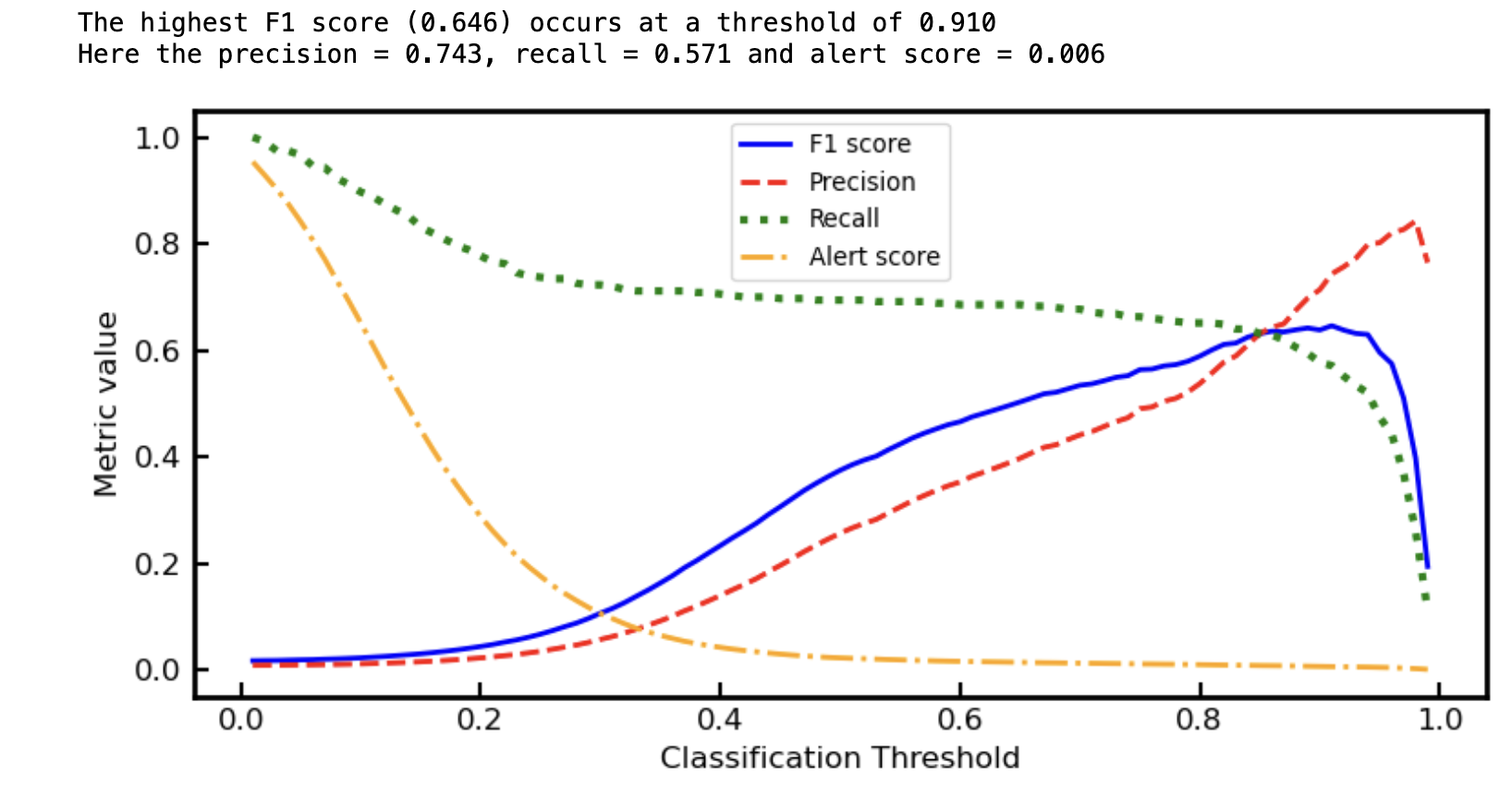
Threshold Optimisation
Rather than using a fixed threshold, the model output probabilities were tuned to optimise performance. The optimal threshold (~0.91) was selected to:
- Maximise F1 score
- Maintain a low alert rate
- Keep precision high for operational usability
Evaluation
Confusion Matrix (Final Model)
| Predicted Legit | Predicted Fraud | |
|---|---|---|
| Actual Legit | 41061 | 69 |
| Actual Fraud | 150 | 200 |
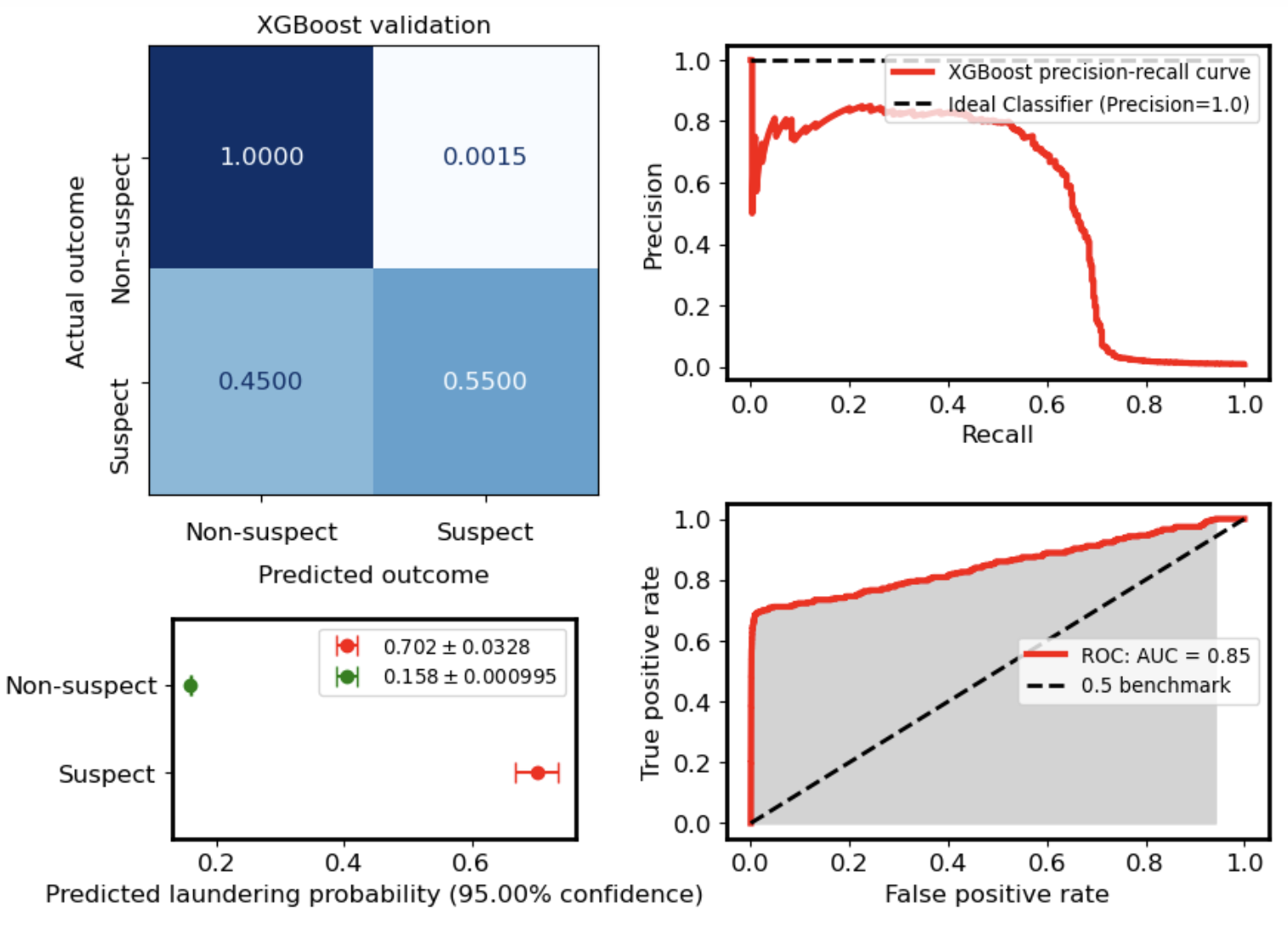
Interpretation
- High precision → low false alarm rate
- Moderate recall → some fraud remains undetected
- Suitable for real-world triage systems
Note: Due to class imbalance, the normalized confusion matrix shows near-perfect true negatives. This reflects dataset composition rather than perfect model performance.
Key Insight
This project demonstrates that model performance in real-world ML is about trade-offs, not perfection
A useful fraud model must:
- Catch enough fraud (recall)
- Avoid overwhelming analysts (precision)
- Operate at a realistic alert rate
Technologies Used
- Python
- scikit-learn
- imbalanced-learn
- pandas / numpy
- matplotlib
Future Improvements
- Cost-sensitive learning (fraud vs investigation cost)
- Feature engineering / domain features
- Model calibration
- Deployment as a scoring pipeline