
Fast Lie algebra multiplication for all five exceptional algebras (G₂, F₄, E₆, E₇, E₈) using sparse structure constants. Eight modules: equivariant PyTorch layers, JAX backend, lattice gauge theory, RKMK Lie group integrators, quantum simulation, PyTorch Geometric integration, and a C++ extension hitting 993× over dense.
pip install dhl-mm
Left: the computation — sparse gather-multiply-scatter over nonzero structure constants
$\mathcal{F}(\mathfrak{g})$ , with Z[φ] lattice projection$\Pi^{h^2}_\varphi$ for error control. Right: why it works — no exceptional algebra has a degree-3 Casimir invariant, so the symmetric$d$ -tensor vanishes and antisymmetric constants capture the full product.
import dhl_mm
# Load any exceptional algebra — cached, <25ms
e8 = dhl_mm.algebra("E8")
g2 = dhl_mm.algebra("G2")
# Sparse Lie bracket (913× fewer ops than dense for E8)
import numpy as np
x, y = np.random.randn(248), np.random.randn(248)
z = e8.bracket(x, y)from equivariant import SparseLieBracket
import torch
bracket = SparseLieBracket.from_algebra("E8") # or "G2", "F4", "E6", "E7"
x = torch.randn(248, requires_grad=True)
y = torch.randn(248)
z = bracket(x, y) # full autograd support
z.sum().backward() # gradients flow through sparse scatter-addfrom equivariant import ExceptionalEGNN
model = ExceptionalEGNN(
in_dim=14, hidden_dim=32, out_dim=1,
n_layers=3, algebra_name="G2", equivariant=True
)
nodes = torch.randn(10, 14)
edge_index = torch.tensor([[0,1,2,3],[1,2,3,0]], dtype=torch.long)
prediction = model(nodes, edge_index)from dhl_mm.pyg import LieBracketConv # requires torch_geometric
conv = LieBracketConv("E8", equivariant=True)
out = conv(node_features, edge_index) # equivariant message passingfrom dhl_mm import GaugeLattice
lat = GaugeLattice((8, 8), algebra_name="E8") # 8×8 lattice, E8 gauge group
lat.hot_start(scale=0.5)
result = lat.thermalize(n_sweeps=100, beta=1.0)
print(f"Average plaquette: {result['average_plaquettes'][-1]:.4f}")from dhl_mm import RKMKIntegrator
rk = RKMKIntegrator("E8")
flow = lambda t, y: rk.alg.bracket(H, y) # adjoint flow dy/dt = [H, y]
result = rk.solve(flow, y0, t_span=(0, 1), dt=0.01, method='rk4')
# 4th-order convergence with BCH bracket correctionsfrom dhl_mm import E8SpinLattice
lattice = E8SpinLattice(n_sites=8, algebra_name="E8")
state = lattice.random_initial_state()
trajectory = lattice.evolve(state, dt=0.001, steps=500, order=2)
# 8 sites × 500 steps in ~4 seconds on CPUfrom dhl_mm import jax_algebra
alg = jax_algebra("E8") # JIT-compiled sparse bracket
z = alg.bracket(x, y) # automatic differentiation via custom_jvp
zs = alg.batch_bracket(xs, ys) # vmap over batch dimensionLie-algebra-valued lattice dynamics under adjoint commutator flow. The sparse bracket makes it feasible to simulate E₈-valued spin chains on CPU.
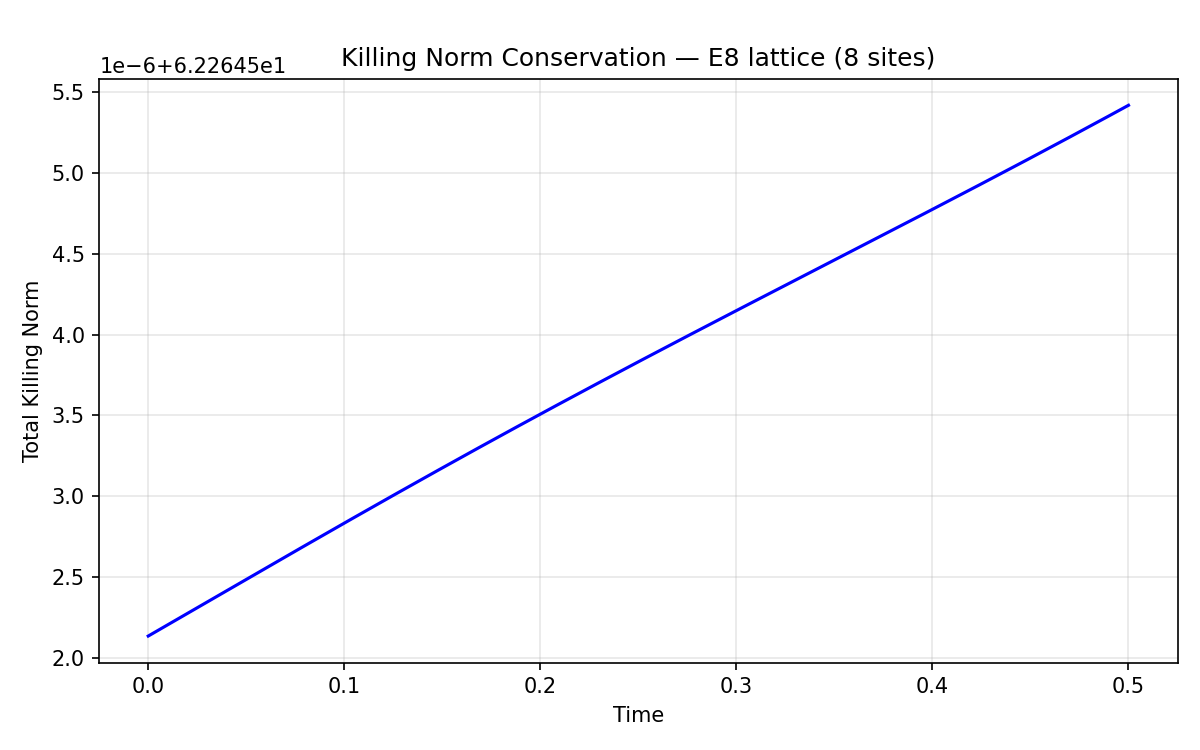
Killing norm conservation — flat line proves the integrator preserves algebraic structure. Drift ~3×10⁻⁶ over 500 steps.
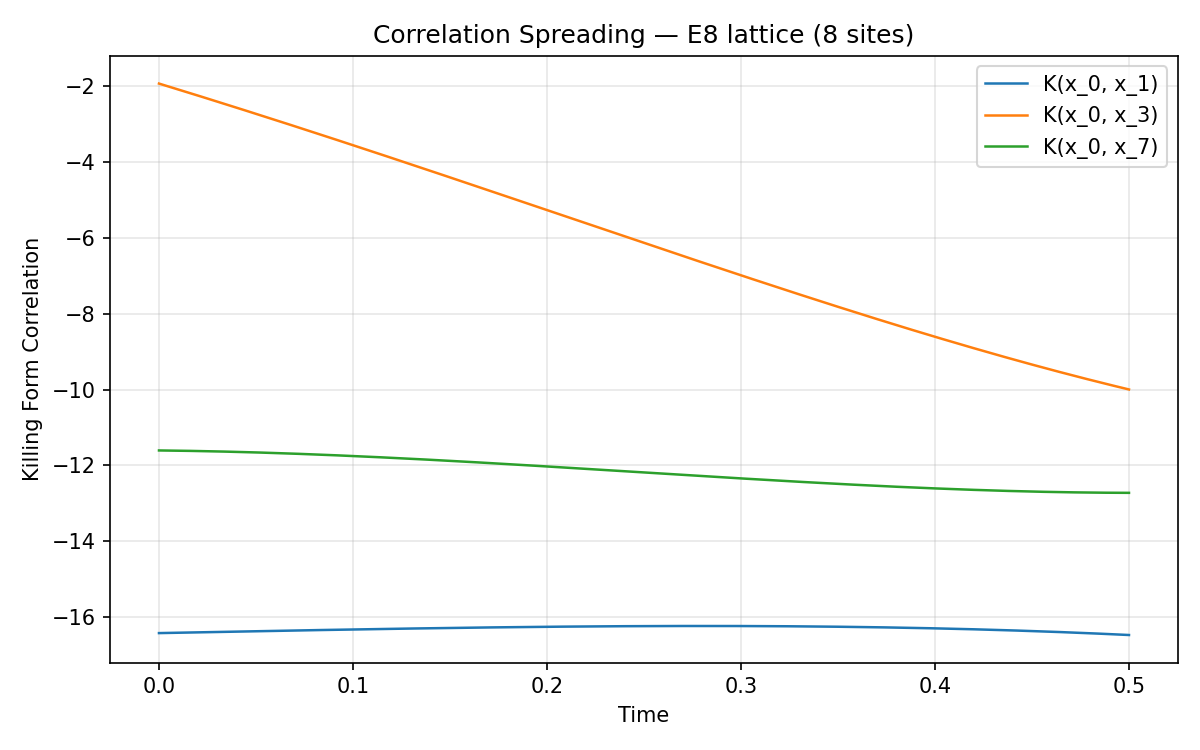
Correlation spreading — Killing inner product between sites shows information propagation across the lattice.
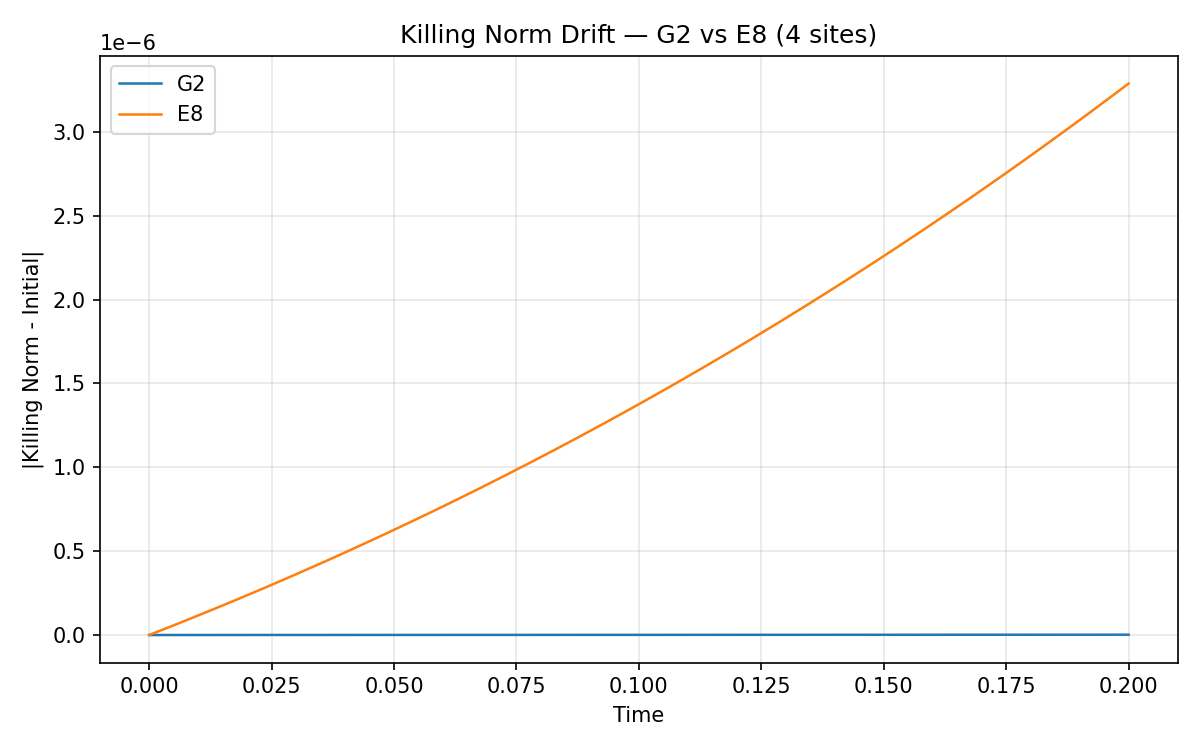
G₂ vs E₈ — same lattice geometry, different algebras. G₂ (14-dim) drifts ~10⁻⁹, E₈ (248-dim) drifts ~10⁻⁶. Both well-conserved.
| Algebra | Dim | Roots | Nonzero f | Full n³ | Compression | Jacobi Error |
|---|---|---|---|---|---|---|
| G₂ | 14 | 12 | 120 | 2,744 | 22.9× | ~1e-14 |
| F₄ | 52 | 48 | 1,196 | 140,608 | 117.6× | ~1e-16 |
| E₆ | 78 | 72 | 2,208 | 474,552 | 215× | ~1e-13 |
| E₇ | 133 | 126 | 5,544 | 2,352,637 | 424× | ~1e-13 |
| E₈ | 248 | 240 | 16,694 | 15,252,992 | 913× | ~1e-16 |
All algebras verified to machine epsilon. No approximations. See NUMERICAL_PRECISION.md for detailed FP64 error bounds.
None of the exceptional Lie algebras have a cubic Casimir invariant:
| Algebra | Casimir Degrees |
|---|---|
| G₂ | 2, 6 |
| F₄ | 2, 6, 8, 12 |
| E₆ | 2, 5, 6, 8, 9, 12 |
| E₇ | 2, 6, 8, 10, 12, 14, 18 |
| E₈ | 2, 8, 12, 14, 18, 20, 24, 30 |
No degree 3 means the symmetric structure constants d_{ij}^k vanish identically for all five. The full product T_i·T_j projected onto the Lie algebra equals [T_i, T_j]/2 exactly. The entire product is determined by the antisymmetric structure constants alone.
Instead of multiplying n×n matrices, the product of two Lie algebra elements X = Σ xᵢTᵢ, Y = Σ yⱼTⱼ is:
(XY)_k = (1/2) Σ_{(i,j,k) ∈ f} xᵢ · yⱼ · f_{ij}^k
where f_{ij}^k are precomputed sparse entries. This is a gather-multiply-scatter operation. Structure constants are precomputed and shipped as .npz files — first algebra load takes <25ms.
Coefficients stored as integer pairs (a, b) representing a + bφ where φ is the golden ratio. Multiplication uses φ² = φ + 1. No floating-point accumulation errors for algebraic inputs.
h²(t) = h²_Λ - (κ/3) · ρ_defect(t)
Tracks accumulated deviation from the Z[φ] lattice. When h²(t) drops below threshold, coefficients are projected back to the nearest lattice point. Self-correcting computation.
AdjointLinearLayer— by Schur's lemma, the only linear map commuting with the adjoint action is a scalar multiple of the identity. Single learnable parameter.AdjointBilinearLayer— the two independent adjoint-invariant bilinear operations: antisymmetric bracket + symmetric Killing form scalar.EquivariantLieConvLayer— message passing with bracket-based nonlinearityx + α·[agg, W(agg)], following the Lie Neurons pattern (Lin et al. 2024). Adjoint equivariance verified to ~1e-15 for all 5 algebras.LieBracketConv— PyTorch GeometricMessagePassinglayer, drop-in compatible with any PyG pipeline.
LieHamiltonian— sparse commutator[H, ρ]for Lie-algebra-valued time evolution.EquivariantTrotterSuzuki— first and second-order integrators with Killing norm drift tracking.E8SpinLattice— nearest-neighbor coupled evolution on a 1D lattice of algebra-valued sites. 8-site E₈ lattice evolves in ~4s on CPU with Killing norm drift ~3×10⁻⁶.
GaugeLattice— link variables, plaquettes, staples, Wilson loops (rectangular + Polyakov), and Metropolis updates for exceptional gauge groups. First open-source tooling for E₈/F₄ lattice gauge theory.- 8×8 E₈ lattice thermalizes in ~1.4s (100 sweeps). Acceptance rate ~52%.
RKMKIntegrator— Euler, RK2, and RK4 with Baker-Campbell-Hausdorff bracket corrections for geometric structure preservation. Verified 4th-order convergence.LieGroupFlow— convenience wrappers for rigid body dynamics, adjoint flow, and Yang-Mills evolution.- E₈ rigid body Killing norm drift ~2×10⁻⁹ over 1000 steps.
JaxSparseBracket— JIT-compiled sparse bracket withcustom_jvpfor forward-mode AD.vmapbatch support.JaxLieAlgebra— convenience wrapper withbracket(),killing_form(),batch_bracket().- JAX is optional — module imports cleanly without it.
from dhl_mm import jax_algebra
alg = jax_algebra("E8")
z = alg.bracket(x, y) # JIT-compiled, differentiableA pybind11 C++ sparse kernel with OpenMP batched support is included (dhl_mm/csrc/). 993× speedup over dense on CI hardware. Falls back to NumPy if not compiled. Prebuilt wheels for Linux, macOS, and Windows are built automatically via cibuildwheel on each release.
pip install pybind11 && python setup.py build_ext --inplace # manual builddhl_mm/ Core library (pip install dhl-mm)
__init__.py algebra() / jax_algebra() factories, cached loading
exceptional_engine.py ExceptionalAlgebra class for all 5 algebras
roots.py Root system builders (G2, F4, E6, E7, E8)
structure.py Structure constant computation (Chevalley basis)
casimir.py Casimir degree analysis + d-tensor verification
quantum.py Trotter-Suzuki evolution + E8 spin lattice
lattice.py Lattice gauge theory (plaquettes, Wilson loops, Metropolis)
integrators.py RKMK Lie group integrators (Euler, RK2, RK4 + BCH)
jax_backend.py JAX sparse bracket with custom_jvp + vmap
e8.py E8 root system + Frenkel-Kac cocycle
engine.py DHLMM class (original E8 engine)
zphi.py Exact Z[phi] arithmetic
defect.py Friedmann-style h²(t) error tracker
pyg.py PyTorch Geometric LieBracketConv layer
csparse.py C extension wrapper with numpy fallback
csrc/sparse_bracket.cpp pybind11 C++ sparse kernel with OpenMP (optional)
data/*.npz Precomputed structure constants (5 algebras)
equivariant/ PyTorch equivariant neural network layers
sparse_kernel.py SparseLieBracket, SparseKillingForm (differentiable)
layers.py LieConvLayer, EquivariantLieConvLayer, AdjointLinearLayer
model.py ExceptionalEGNN architecture
benchmark.py Multi-algebra benchmark suite
tests/test_equivariance.py Equivariance, gradients, consistency (8 tests)
exceptional/ Backward-compatible re-exports (delegates to dhl_mm/)
tests/test_all.py All 5 algebras: Jacobi, antisymmetry, Killing (7 tests)
benchmarks.py Compression ratio table
tests/ Test suites
test_quantum.py Quantum simulation: conservation, Trotter accuracy (9 tests)
test_lattice.py Lattice gauge: plaquettes, Metropolis, Wilson loops (7 tests)
test_integrators.py RKMK: convergence order, Killing conservation (7 tests)
test_jax_backend.py JAX: correctness, gradients, vmap, JIT (8 tests)
test_fp64.py FP64 precision bounds, dtype enforcement (4 tests)
examples/ Demo scripts with output plots
quantum_sim_demo.py E8 spin lattice simulation + G2 vs E8 comparison
lattice_gauge_demo.py E8 lattice gauge thermalization + Wilson loops
integrators_demo.py RKMK convergence test + rigid body demo
notebooks/ Interactive demos (Colab-ready)
e8_in_5_minutes.ipynb All 5 algebras, benchmarks, equivariance
equivariant_gnn_demo.ipynb Train an equivariant GNN on synthetic data
benchmarks/ Performance benchmarks
sparse_kernel_bench.py C extension vs numpy vs dense, all algebras
scripts/ Build utilities
precompute.py Generate .npz structure constant caches
.github/workflows/ CI/CD
ci.yml Build, test, benchmark on push (Python 3.10 + 3.12)
wheels.yml cibuildwheel: prebuilt C extension wheels on release
50+ tests across 7 suites:
# Core algebra tests
python exceptional/tests/test_all.py # All 5 algebras: Jacobi, antisymmetry, Killing (7)
python test_structure.py # E8 structure constants verification
python test_full_algebra.py # E8 full 248-dim algebra
# Module tests
python equivariant/tests/test_equivariance.py # Equivariance, gradients, consistency (8)
python tests/test_quantum.py # Quantum sim: conservation, Trotter accuracy (9)
python tests/test_lattice.py # Lattice gauge: plaquettes, Metropolis (7)
python tests/test_integrators.py # RKMK: convergence order, conservation (7)
python tests/test_jax_backend.py # JAX: correctness, gradients, vmap (8)
python tests/test_fp64.py # FP64 precision bounds, dtype enforcement (4)
# Benchmarks
python equivariant/benchmark.py # Sparse vs dense timing, all algebras
python benchmarks/sparse_kernel_bench.py # C extension vs numpy vs dense
# Demos (generate plots in examples/)
python examples/quantum_sim_demo.py # E8 spin lattice + conservation plots
python examples/lattice_gauge_demo.py # Thermalization + Wilson loops
python examples/integrators_demo.py # RKMK convergence + rigid bodyShipped — working modules in the package:
- Quantum simulation — Trotter-Suzuki evolution on Lie-algebra-valued spin lattices
- Lattice gauge theory — first open-source tooling for E₈/F₄ gauge groups
- Lie group integration — RKMK integrators with BCH corrections
- Equivariant neural networks — adjoint-equivariant layers, PyG compatible
- JAX-accelerated computation — JIT-compiled sparse brackets with vmap
Future directions:
- Post-quantum cryptography (E₈ lattice operations)
- Tensor network contraction (exceptional symmetry groups)
- Clifford algebra acceleration (geometric computing)
- E₈ error-correcting codes
See APPLICATIONS_ROADMAP.md for details.
- Python ≥3.9
- NumPy ≥1.20
Optional:
- PyTorch ≥2.0 — equivariant layers, differentiable bracket
- JAX ≥0.4 — JAX backend with JIT and custom_jvp
- SciPy ≥1.10 — equivariance tests (matrix exponential)
- torch_geometric —
LieBracketConvPyG layer - pybind11 — build C++ extension from source (993× speedup)
- matplotlib — demo plots
MIT