Neste repositório é feita a implementação dos algoritmos de deep reinforcement learning DQN e DRQN em python. O Deep Q-Network (DQN) introduzido pelo artigo Human-level control through deep reinforcement learning[1] é um algoritmo que aplica redes neurais profundas (deep learning) ao problema de reinforcement learning (aprendizado por reforço). O objetivo do reinforcement learning é, basicamente, o de ensinar uma inteligência artificial, chamada de agente, como mapear o estado atual em que se encontra no ambiente em ações, de tal forma a maximizar a premiação ao final da tarefa. No caso do DQN, os estados são imagens da tela do ambiente. Logo, a rede neural profunda é treinada a medida em que o agente interage com o ambiente (via reinforcement learning), de tal forma a transformar esses dados de alta dimensão (imagens) em ações (botões a serem pressionados). Já o Deep Recurrent Q-Network (DRQN) é uma versão do DQN proposta pelo artigo Deep recurrent q-learning for partially observable mdps[2] que substitui a primeira camada densa da rede neural profunda do DQN por uma do tipo recorrente (LSTM). Desta forma, o agente treinado por esse algoritmo lida melhor com ambientes parcialmente observáveis como, por exemplo, os mapas tridimensionais do ViZDoom.
Embora existam inúmeros scripts que implementem os algoritmos descritos acima, a maioria os implementa de uma maneira simples sem se preocupar com o desempenho, ou seja, quanto tempo de simulação levará e consequentemente a energia gasta no processo para treinar os agentes. Para otimizar o desempenho dos algoritmos, os scripts nesse repositório aproveitam o máximo da computação vetorizada pelas bibliotecas Numpy e Tensorflow para reduzir o tempo de simulação gasto para treinar os agentes. Além disso, foi desenvolvido um método para diminuir consideravelmente (alguns exemplos tiveram a redução no tempo de simulação em 30%) o tempo necessário de simulação, ao paralelizar de forma simples os algoritmos DQN/DRQN (mais detalhes sobre as otimizações de desempenho no tópico performance).
Outro aspecto importante que deve ser levado em conta além da performance é a experiência do usuário. Os scripts desse repositório foram feitos de tal forma a dar uma maior flexibilidade na escolha dos parâmetros de simulação, sem a necessidade de alteração dentro do código principal. O usuário tem total controle sobre a simulação, podendo definir suas próprias arquiteturas de redes neurais, simular com frames coloridos e de tamanho desejado e escolher qualquer um dos ambientes de Atari 2600 oferecidos pela biblioteca GYM ou dos mapas tridimensionais do ambiente ViZDoom. Além disso, este repositório apresenta possibilidade de visualização do agente treinado pelo modo teste, renderização ou não para o usuário, continuação de treinamento, transfer learning entre outros (mais detalhes em características do código).
Aos desenvolvedores e interessados, cabe salientar que todos os códigos pertencentes a esse repositório - funções e classes - encontram-se comentados para facilitar o entendimento.
- Modo de execução em paralelo do algoritmo de RL disponível (chegando a ser 30% mais rápido que o modo padrão).
- Ambientes bidimensionais (OpenAi Gym) e tridimensionais (ViZDoom) para o treinamento e teste de agentes.
- Dois mapas exclusivos para o ViZDoom simulando um problema de robótica móvel.
- Configuração do treinamento/teste do agente via comandos no terminal ou via arquivos de configuração .cfg (Ver as sessões de exemplos e a documentação).
- Armazenamento de informações do treinamento em arquivos .csv (mais detalhes aqui) e dos pesos das redes neurais como .h5.
- Facilidade e robustez para definir os hiperparâmetros sem a necessidade de modificar o código (Ver a sessão dos arquivos .cfg).
- Facilidade para a criação de arquiteturas de redes neurais sem a necessidade de modificar o código principal (Ver a sessão Definindo a arquitetura da rede neural).
- Simulação com frames monocromáticos ou coloridos (RGB) (mais detalhes aqui).
- Armazenamento dos episódios ao longo do treinamento e dos estados ao longo de um teste como imagens .gif.
- Pesos pré-treinados para o mapa labyrinth de ViZDoom acompanhando esse repositório (mais informações aqui).
Durante o desenvolvimento do algoritmo foram buscadas as melhores maneiras de aumentar o processamento de frames/segundo. A parte que demanda mais tempo de processamento é a utilização das redes neurais. Durante o cálculo do erro de treinamento das redes neurais, necessitamos dos resultados de ambas as redes neurais Q e Q_target para todas as N amostras colhidas da replay memory. Logo, essa parte do código foi pensada de forma a aproveitar o máximo da computação vetorizada, assim for loops em python nativo foram substituídos pela vetorização em Numpy (principal biblioteca matemática do python) e posteriormente foram mudados para vetorização em Tensorflow. Assim, se o usuário possuir uma GPU, o código tomará vantagem do paralelismo massivo fornecido pela mesma para a execução mais rápida do algoritmo.
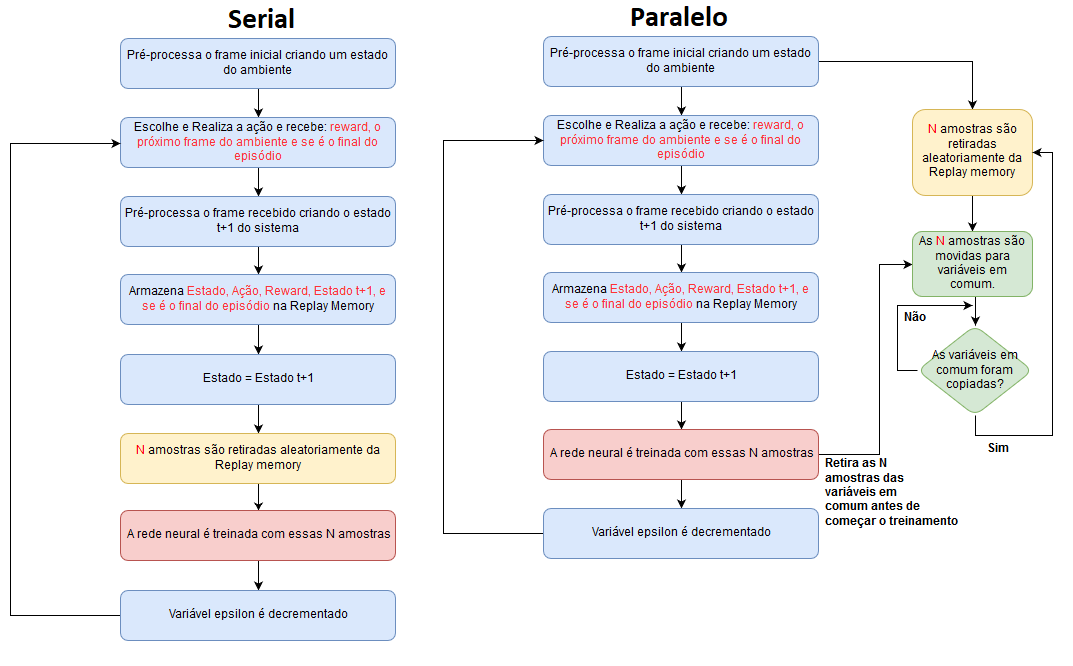
Depois do uso das redes neurais, a parte que mais utiliza recursos de processamento é a amostragem das experiências a medida que replay memory for preenchida. Para uma atenuação deste problema foi desenvolvida uma abordagem de processamento em paralelo (multi-threading) para os algoritmos DQN e DRQN. O modo em paralelo consiste basicamente em amostrar as experiências da replay memory paralelamente enquanto o algoritmo de decisão é executado. Assim, quando chegamos na parte de treinamento da rede neural o custo computacional da amostragem já foi executado. A figura a seguir demonstra como são executadas as abordagens serial (single-threading) e paralelo (multi-threading).
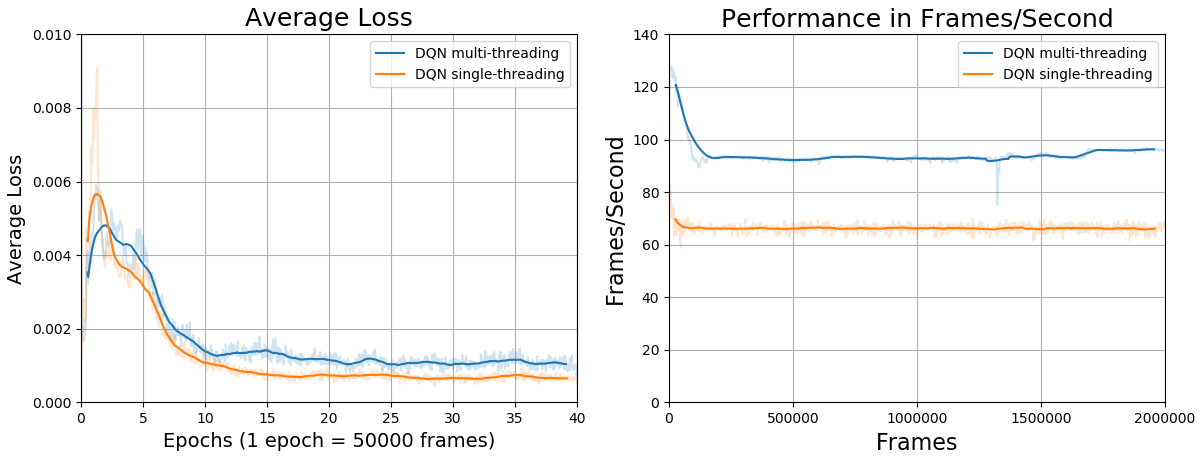
| Processamento | Frames/segundo em média | Tempo de simulação |
|---|---|---|
| Serial | 94.9 | 5 horas e 54 minutos |
| Paralelo | 66.39 | 8 horas e 23 minutos |
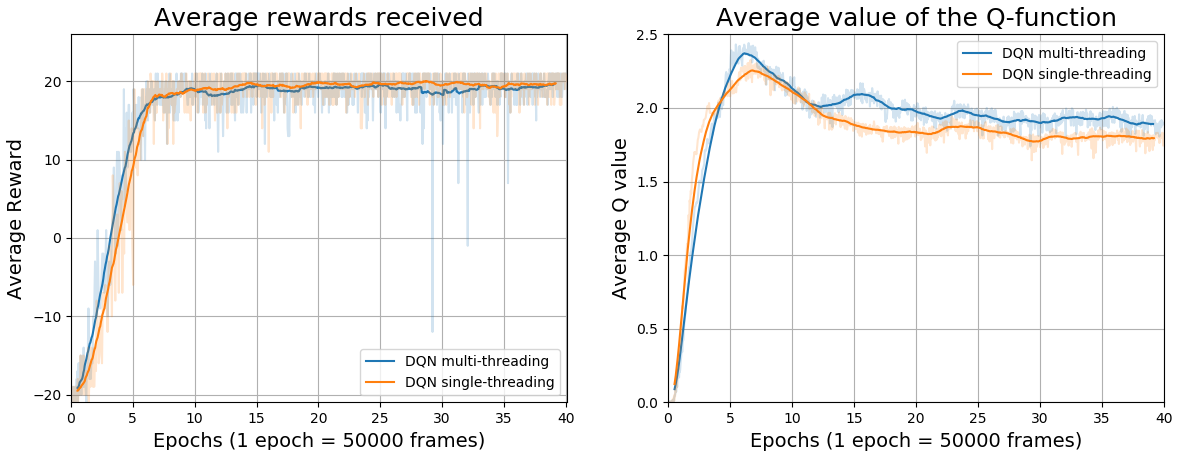
Um ponto importante a se ressaltar na abordagem em paralelo é o fato que a mesma introduz um atraso de uma amostragem no algoritmo. Ou seja, a experiência de uma iteração t só poderá ser amostrada na próxima iteração t+1. Isto é devido ao fato que a amostragem já vai ter ocorrido no momento que o agente estiver interagindo com o ambiente. Entretanto, como podemos observar pelas imagens do treinamento abaixo, o processo de aprendizagem é minimamente afetado. De fato, como todas as experiências são amostradas uniformemente da replay memory, com a memória cheia com 100 mil experiências, temos a probabilidade 0.001% de uma experiência ser escolhida. Assim, podemos concluir que o processo de aprendizagem dos algoritmos DQN e DRQN é robusto o suficiente ao ponto de não ser afetado por este atraso de uma amostragem. Assim, o modo multi-threading é recomendado para as simulações realizadas utilizando os scripts deste repositório devido a seu processamento mais rápido.
- Instalação
- Documentação
- Arquivos de configuração .CFG
- Definindo a arquitetura da rede neural
- Informações sobre os mapas deste repositório (ViZDoom)
- Informações sobre os pesos pré-treinados
- Exemplos
Se esse código foi útil para sua pesquisa, por favor considere citar:
@misc{LVTeixeira,
author = {Leonardo Viana Teixeira},
title = {Desenvolvimento de um agente inteligente para exploração autônoma de ambientes 3D via Visual Reinforcement Learning},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
url = {https://github.com/vtleonardo/Reinforcement-Learning},
}
- [1] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529, 2015.
- [2] Matthew Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. CoRR, abs/1507.06527, 2015.
- [3] Max Lapan. Speeding up dqn on pytorch: how to solve pong in 30 minutes. 23 de novembro 2017. Disponível em https://medium.com/mlreview/speeding-up-dqn-on-pytorch-solving-pong-in-30-minutes-81a1bd2dff55. Acesso em: 07 de novembro de 2018.
- [4] Daniel Seita. Frame Skipping and Pre-Processing for Deep Q-Networks on Atari 2600 Games. 25 de novembro de 2016. Disponível em https://danieltakeshi.github.io/2016/11/25/frame-skipping-and-preprocessing-for-deep-q-networks-on-atari-2600-games/. Acesso em: 04 de janeiro de 2019.