| title | Java基础(集合/异常/IO) |
|---|---|
| date | 2020-03-05 09:40:06 -0800 |
演示中老师没用泛型,泛型主要是针对安全问题,后续会讲到
| Method | Description |
|---|---|
| boolean add(E e) | 之所以会返回boolean是为了服务Set的 |
| boolean remove (Object o) | N/A |
| void clear() | N/A |
| boolean contains(Object o) | N/A |
| boolean isEmpty() | N/A |
| int size() | N/A |
这里多说一嘴吧,出现了知识盲区。
像下面这样传进对象的话,实际上发生了父类引用指向子类对象。想用 Student[] 来接受是不可以的!!! 不用Collection用 ArrayList 来创建集合来存也不行,因为集合的 toArray 返回类型就定死在了 Object 类
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(new Student("张三", 23)); // Object obj = new Student("张三", 23);
coll.add(new Student("李四", 24));
coll.add(new Student("王五", 25));
Object[] arr = c.toArray();
for (int i = 0; i < arr.length; i++) {
Student s = (Student)arr[i]; // 向下转型
System.out.println(s.getName() + " ... " + s.getAge);
}
}Java里有一个叫 Iterator 的类,迭代器,Collection下的类都含有 .iterator 的方法,会返回一个 Iterator。Iterator 含有 .hasNext() 和 .next() 方法,一个判断有误,有一个获取到下一个。
这里需要注意一点!!! .next() 获取到的是一个 Object 对象,没办法直接调用里面的特有的方法。(除非用泛型)
普通for循环:
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("b");
list.add("c");
list.add("d");
for(int i = 0; i < list.size(); i++) {
if("b".equals(list.get(i))) {
list.remove(i--); // 这个 i-- 目的是为了保证还指同一个位置,因为删除一个之后是把后面的拼接过来的
}
}Iterator:
// 创造list的过程省略
Iterator<String> itr = list.iterator();
while(it.hasNext()) {
if("b".equals(it.next())) {
//list.remove("b"); // 并发异常了
it.remove();
}
}Enhanced for:
增强 for 循环只能遍历,不能删除。因为它底层用的是 Iterator 来实现的,所以当调用类自己的 remove 方法的时候,还是会出现并发异常。
for (String str : list) {
if ("b".equals(str)) {
list.remove("b");
}
}又出现了一个只是盲区... List 中的 remove 方法是会返回一个 Object 对象的,换句话说就是可以接收到。(应该可以用来做一些奇怪的事)
这里再多注意一件事,当 List 操作整数的时候,直接 remove 的话记得强转成Integer
当一个 List 调用 .iterator() 方法,得到一个迭代器的时候,如果在迭代的过程中对该 list 进行修改,会抛出 "ConcurrentModificationException" 的异常,具体原因和并发有关。
List list = new ArrayList();
list.add("a");
list.add("b");
list.add("World");
list.add("c");
list.add("d");
Iterator itr = list.iterator();
while(itr.hasNext()) {
String str = (String)itr.next();
if("World".equals(str)) {
list.add("javaEE");
}
}
// 以上代码执行就会抛出异常所以如果想用迭代器得到每一个元素,同时还想对 List 进行修改的话,可以使用 List 特有的迭代器:ListIterator
ListIterator litr = list.iterator();
while(litr.hasNext()) {
String str = (String)litr.next();
if("World".equals(str)) {
litr.add("javaEE"); // 注意这里是在 World 之后插入一个 javaEE
}
}
// 它还能检查前一个 .hasPrevious() 也能获取到前一个 .previous() 很少用,作为了解。这里还是多说一嘴,容易被忽略。因为 .contains() 方法依赖的是 .equals(),所以注意要重写,下面以 Person 类举例。再多说一句,.remove() 方法也是依赖的 .equals() 方法,想移除自定义对象也需要重写。
@Override
public boolean equals(Object obj) {
Person p = (Person)obj; // parameter用Object来接受会好一点
return this.name.equals(p.getName()) && this.age == p.getAge();
}这里只写自己的盲区
public class Tool<Q> {
private Q q;
public getObj() {
return q;
}
public setObj(Q q) {
this.q = q;
}
public<T> void show(T t) {
Stsrem.out.println(t);
}
}类名改变可以规定在创建对象的时候,传入的类型;同时有一点注意,单一的方法也可以拥有自己特有的泛型。比如这里的 show 方法,可以传给 show 的就不局限于Q。例如,我创建一个 Tool 的类,规定只能用 Student ,但是当我调用 show 方法的时候,就可以传入任意类型的数据,不局限于 Q。方法想有自己的泛型需要在方法的开头处声明。(一般来说方法的类型与类的泛型一样)
再再再多说一个东西,以上针对的是非静态方法才这么说的,当一个方法是 static 的时候,注意声明泛型。静态方法可以在不创造实例对象的时候调用使用,不控制传参类型会存在安全隐患。
格式:
public <泛型类型> 返回类型 方法名(泛型类型 变量名)
大概知道怎么用的就行了,回头细学的时候在来增加
interface Inter<T> {
public void show(T t);
}
class Demo implements Inter<Person> {
@Override
public void show(Person p) {
System.out.println(t);
}
}通配符就是一个问号 "?"
ArrayList<?> list1 = new ArrayList<Integer>();当引用指向的类型不确定时,可以在左面用通配符。
进阶用法:
Collection中有一个 addAll() 的方法,它API是这么写的:
addAll(Collection<? extends E> e)大概解释一句,往一个集合中添加的,首先必须都要是Collection下面的,而且传进来的集合中的元素,必须是和该集合中的元素是继承关系,或者一样。用下面代码举例说明。
ArrayList<Person> list1 = new ArrayList<>();
list1.add(new Person("张三", 23));
list1.add(new Person("王五", 25));
ArrayList<Student> list2 = new ArrayList<>();
list2.add(new Student("赵六", 26));
list2.add(new Studebt("郑七", 27));
list1.addAll(list2);
// list2.addAll(list1); // 错误使用Collection<? extends E> c
Comparator<? super E> comparator
区别:(个人理解,全以 TreeSet 举例)
? super E --------> TreeSet <-------- ? extend E
从广义的角度来说,创造一个类和一堆子类的时候,他们是一种继承关系,是 is-a 的关系。比如,定义一个 Animal 类,那么 Cat 也是 Animal,Dog 也是 Animal,所有的具体的动物的都是 Animal的子类。在对这些对象进行集体性的操作的时候,比如猫科归为一类,哺乳类归为一类,这样的 “归纳” 操作的时候,使用到的是 ? extends E,因为我们不需要考虑他们具体的属性是怎么样的,只需要考虑归属关系。所谓的上边界,是 ? 相对于 TreeSet 中的元素(E) 而言的,这个 E 就是最高层级,? 不可以比 E 的层级更高。
对于 ? super E 来说的话,它的存在是为了保证 ? 必须为 E 的父类,不可以为子类,以此来保证 ? 有的属性或者方法 E 也有,以此来确定通用性。比如在创造 Comparator 的时候,我想对 Student 对象进行排序,这时候创造 Comparator 的时候就要考虑,是创造一个泛型为 Student 的好,还是泛型为 Person 的好,很明显这个类的选择是层级越高越好。所以下边界是 E 对于 ? 而言的,说人话就是 E 是对于 ? 来说最低的层级了,? 不能比它还低。
所以冯老师所说的 “拿过来” 的意思是,一个 TreeSet 把另一个 TreeSet 添加第一个里面的时候,第一个 TreeSet 的元素就为上边界,第二个 TreeSet 中的元素都必须是第一个 TreeSet 中的元素的子类;
而 “放进去” 的意思是说,当进行某种规定的时候,所传入的参数的泛型层级,需高于下边界,也就是 TreeSet 中的元素,以此来最大范围的保证此规则的有效性。
String[] arr = {"a", "b", "c"};
List<String> list = Arrays.asList(arr);这里 asList() 底层实际 return 的是 ArrayList ,即使尝试强转, 用 ArrayList 来接收,也是不被允许的,在源码多加了一个@SafeVarargs (Safe Variable Arguments)。Java 之所以这样做主要是为了保证数组的长度的不可变性,规定不允许进行额外增删操作,但是可以修改,以集合的思想来对数组进行一定的操作。
ArrayLisy<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
String[] arr = list.toArray(new String[10]);
// 其输出位a b c d 和 6个null如果开辟的数组大小比原集合大,则为以上情况,会跟着多余的几个null;反之则和原集合大小一致。
每次往 Set 里添加新的元素的时候,都会算一个新的 Hash code 给这个对象,他们之间不冲突也就不会进行比较。如果 Set 中也想实现存储不重复对象的话,不但需要重写 equals 方法,还需要重写 hashCode 方法。
比如我创建了一个一个 HashSet 里面存 Person 对象,就要重写 Person 类中的 hashCode 和 equals 方法,如果我固定了 hashCode 的返回值,那程序就会一次次的调用 equals 方法,去比较 name 和 age,这样的效率不够高。所以尽可能要保证,一个对象一个独有的 hashCode, 比如张三,23,就是固定了 hashCode 是一个数值,其他的人不管是李四,23,还是王五,25,都应该和张三,23的 hashCode 值不同,这样避免了多次调用 equals 方法,提高效率。
实际开发中呢,用 IDE 自带的重写 hashCode 和 equals 方法就可以。

底层是链表实现的,是 Set 集合中唯一一个能做到怎么存就怎么取的集合对象。因为是 HashSet 的子类,所以保证了元素的唯一性,与 HashSet 的原理一样
TreeSet 用来对元素进行排序的,同时也可以保证元素的唯一性
TreeSet 之所以可以排序,肯定是比较什么之后才可以做到的。如果里面想存自定义对象的话,要注意给该类实现一个 Comparable 接口。
在创造 TreeSet 对象的时候,可以通过创造匿名内部类的方法来实现排序规则,原本是要再外部创造一个类然后重写compare方法,代码大概实现思路如下:
// 对一个 List 进行排序,要求可以有重复元素
public static void sort(List<String> list) {
TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
int num = s1.compareTo(s2);
return num == 0 ? 1 : num; // 这里不返回 0 主要是为了保留重复元素
}
});
ts.addAll(list);
list.clear();
list.addAll(ts);
}无论是 TreeMap 还是 HashSet ,他们都是以 Key 为基础算 Hash 或者 排序的;HashSet 和 TreeSet / HashMap 和 TreeMap 他们都是用的 Hash 和 二叉树,算法书写没必要写两次,实际用一套算法互相调用即可。底层上 Set 是 依赖 Map 实现的。Map 是一个双列集合,当 Set 调用 put 方法的时候,会在 Key 的位置添加所需要添加的元素,然后再 Value 的位置添加一个名为 PRESENT 的空 Object 对象,隐藏 Value。
Map中put相同的 Key 的时候保留,但是 Value 是覆盖。put 方法是有返回值的,返回的是 V,这个 V 是被覆盖的值,以代码来举例:
Map<String, Integer> m = new HashMap<>();
Integer i1 = map.put("张三", 23); // 这里的 i1 是个null,刚初始化 map 对象的时候,K和V都是null
Integer i2 = map.put("张三", 25); // 这里的 i2 是之前的23,把23覆盖掉了remove 方法,根据 Key 来移除一对数据,同时返回 Value 值
利用 KeySet 方法得到,它会返回一个存有全部 Key 的Set,之后用 Iterator 或者 for 循环之类的都可
这里多说一句,可以用 enhanced for loop来让代码很好看:
for (String key : map.KeySet()) {
System.out.println(key))
}使用键值对对象,把这个双列集合的对象作为一个单列集合存在。使用 entryset 方法可以得到
Set<Map.Entery<String, Integer>> es = map.entryset();这里也可以使用 enhanced for loop 来得到没一个键值对
存自定义对象的时候,同样和 HashSet 那面的情况一样,也需要重写 equals 和 hashCode 方法,重写之后才能保证在添加元素进 Map 的时候,Key 值唯一
地层是 HashTable 实现,同时有满足链表结构的 Map。有前后顺序,其他的和正常Map的使用一样。
共同点:地层都是哈希算法,而且都是双列集合
区别:
HashMap 是线程不安全的,效率高,JDK1.2 版本开始出现
Hashtable是现成安全的,效率低,JDK1.0 版本的
HashMap 可以存 null 键和 null 值
Hashtable 不可以
Throwable 下有两个子类,一个是 Error 另一个是 Exception。一般 Error 都是一些致命报错,比如服务器崩溃等。Exception 这里暂时重点讲的是 RuntimeException,即运行时异常。这样的异常大多数都是由程序员自身的操作失误而导致的,需要回头修改代码。
说使用之前先区别一下客户端(安卓)开发和服务端(EE)开发中,使用的差别。
安卓中的实际开发,一般直接一个 try{} catch (Exception e) {} 一次直接全捕获到就完事了。
服务端开发中,是要从底层一层层向上抛出,记录下来的,这样有助于记录和维护。
Try... Catch,在 Try 中,它会检测有没有某一个具体的异常对线产生,如果有的话,就会让 Catch给捕获过去。让 catch 中的那个 e 给接过去了。
public static void main(String[] args) {
try {
// code ///
}
catch (Exception e) {
// code //
}
}Try... Catch 是有先后顺序的,如果 Catch 的异常顺序像上述这样,它不管什么样的异常都会直接接过去,从而没办法确定具体的异常类型。所以,如果为了更好的维护和记录的话,要遵循越详细的前面越笼统的放外面,这是基于多态的。
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream("XXX.txt");
} catch (Exception e) {
}
}以上就是在编译时会产生的错误,那个 XXX.txt 如果不存在的话就会抛出异常,在编译之前就要去修改。但是如果有需要这样写的话,就需要用 try 来处理。
- getMessage(): 获取到异常信息,返回 String
- toString(): 获取异常类名和异常信息,返回字符串
- printStackTrace(): 获取异常类名和异常信息,以及异常出现在程序中的位置,返回为void
Java 中的 throw 其实和 Python 里的 raise 用法一样,直接 throw + 异常对象即可
throw new Exception("XXX");需要注意的是,如果抛出的异常是一个 RuntimeException 的话,在方法上是不需要加写 throws 关键字的。很好理解,如果直接抛出 Exception 的话,这里包含了编译时异常和运行时异常,如果不缩小到运行时异常的话,那我们的代码也需要顾全编译时异常。
所以编译时异常的抛出是必须要对其进行处理的,但是运行异常的抛出可以处理也可以不处理。
throws:
- 跟在方法声明后面
- 可以跟多个异常类名且用逗号隔开
- 表示抛出异常,由该方法的调用者来处理
throw:
- 用在方法内,后面跟的是一个异常对象
- 只能抛出一个异常对象
- 表示抛出异常,由方法体内的语句处理
它的存在是为了释放资源,在 IO 流操作和数据库操作中会见到,被 finally 控制的语句体一定会执行,除非在执行到 finally 语句之前 JVM 就退出了。
public static void main(String[] args) {
try {
// code //
} catch (Exception e) {
return 0;
} finally {
// execution //
}
}这里,无论 catch 中的代码执行还是没执行,finally 里的语句都会执行,就算在 catch 里有 return 语句。
finally 比正常想的要复杂的多,地层 JVM 的处理方式比较特殊,直接上代码
class Test {
public static void main(String[] args) {
System.out.println(getValue());
}
public static int getValue() {
int i = 1;
try {
i++;
return i;
} finally {
i += 50;
}
}
}首先要明白的是,finally 的代码块的执行时间,是在 JVM 执行 ireturn 之前的,也就是说,return i 不是马上执行,而是在执行完 i += 50 之后才把 i 的值返回给 main 函数中的调用者的。它会在 try 中执行 i++ 之后,把 i 的值存在 Local Variable Table 的一个位置(似乎是最后一位?)然后再返回,具体字节码文件如下,已附详细注释。
public static int getValue();
descriptor: ()I // 数据类型
flags: (0x0009) ACC_PUBLIC, ACC_STATIC // Access 修饰符类型
Code:
stack=1, locals=3, args_size=0
0: iconst_1 // line 7: 产生一个值为 1 的数
1: istore_0 // 存在 Local Variable Array 的 index 为 0 的位置
2: iinc 0, 1 // line 9: 把 i + 1 执行
5: iload_0 // line 10: 要执行 return 之前先读取 index 为 0 的这个值
6: istore_1 // 之后存在 Array 的 index 为 1 的位置
7: iinc 0, 50 // 此时 i += 50 是对 Array 里 index 为 0 的那个 2 进行增加的
10: iload_1 // 再次读取 index 为 1 的值
11: ireturn // 把读取到的值 return
12: astore_2 // 可能是产生一个对应的 Exception 对象然后把 reference 存进去?
13: iinc 0, 50 // 只要期间发生异常,还没有 catch 的情况,执行 finally 代码块
16: aload_2 // 把这个 Exception 对象的引用读取到
17: athrow // 把异常对象抛出
Exception table:
from to target type
2 7 12 any // 此处含义为从 2 - 7 步中只要出现异常,则跳转到12
LineNumberTable: // 这个 table 是原 .java 的源码行数对应这里的关键操作行数
line 7: 0
line 9: 2
line 10: 5
line 12: 7
line 10: 10
line 12: 12
line 13: 16
StackMapTable: number_of_entries = 1
frame_type = 255 /* full_frame */
offset_delta = 12
locals = [ int ]
stack = [ class java/lang/Throwable ]继承 Exception / RuntimeException 就行,记得重写一些必要的方法。这个在开发中,很重要,对异常处理的越规范,排查错误的时候就越轻松。
这里通过一个很巧妙的方法来判断输入的非法类型,可以作为案例学习一下
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("输入一个整数:");
while (true) {
String line = sc.nextLine();
try {
int num = Integer.parseInt(line);
System.out.println(Integer.toBinaryString(num));
break;
} catch (Exception e) {
try {
new BigInteger(line);
System.out.println("录入错误,输入了一个过大的整数,重新输入:");
} catch (Exception 2) {
try {
new BigDecimal(line);
System.out.println("录入错误,输入了一个小数,重新输入:")
} catch (Exception e3) {
System.out.println("录入错误,输入了字符,重新输入:")
}
}
}
}
}主要有三种方法
File(String pathname);
File(String parent, String child);
File(File parent, String child);parent 指的是一个目录,child 就是相对 parent 的文件名。第三个构造函数,把 parent 进行一次封装,这样相对来说比 String 形式的路径会更强大一些
又是一些简单的操作...
public boolean createNewFile();
public boolean mkdir();
public boolean mkdirs();上面多说一下,mkdirs 是创建多级目录用的,具体格式如下
File dir = new File("home\\pictures\\2018");
dir.mkdirs(); // 在当前目录下创建这样一个多级目录改名/路径,使用 renameTo 方法
// public boolean renameTo(File dest);
File f1 = new File("xxx.txt");
File f2 = new File("ooo.txt");
f1.renameTo(f2);
// 改名并剪切过去
File f3 = new File("yyy.txt");
File f4 = new File("D:\\zzz.txt");删除文件或文件夹,Java 删除不走回收站,而且要注意,如果删除文件夹的话,需要保证其为空文件夹
File file3 = new File("test.txt");
file3.delet();直接贴图

注意事项:
- Windows 下认为所有文件都可读
- Windows 下可以设为不可写
public String[] list(); // 获取到指定目录下所有的文件或者文件夹的名字
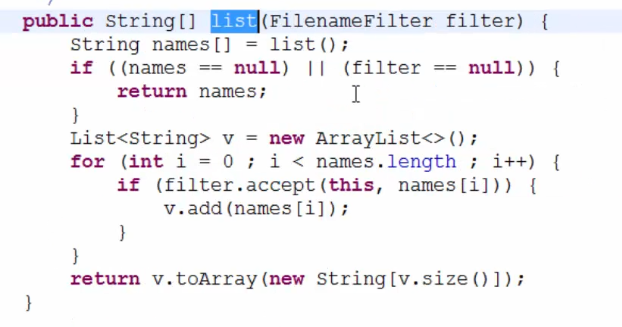
public File[] listFiles(); // 获取指定目录下的所有文件或文件夹File数组这是一个借口,调用 file.list() 的时候可以传入匿名对象,规定过滤规则
String arr = dir.list(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
File file = new File(dir, name);
return file.isFile() && file.getName().endWith(".jpg");
}
});附上源码:
简单概述

这四个都是最顶的抽象父类,往下的话以后缀进行判断。什么什么 Stream 就是字节流,什么什么Reader 或者什么什么 Writer 就是字符流。
基础方面注意两点
- 在使用 fos.write() 的时候,如果不在 constructor 的第二个参给 true 的话就是表示清空重写的操作
- fis.read() 读到最后结尾返回的是 -1 可以作为终止标识
- 文件很大的时候直接 read 然后直接 write 效率会很低
相对高效一点的拷贝方式:
FileInputStream fis = new FileInputStream("AAA.mp3");
FileOutputStream fos = new FileOutpurStream("copy.mp3");
byte[] arr = new byte[fis.available()];
fis.read(arr);
fos.write(arr);
fis.close();
fos.close();
// 不过实际开发中这个也不是推荐使用,因为当拷贝比较大的文件的时候,内存可能吃不住这么大的文件第三种拷贝方式:
FileInputStream fis = new FileInputStream("xxx.txt");
FileOutputStream fos = new FileOutputStream("copy.txt");
byte[] arr = new byte[4];
int len;
while ((len = fis.read(arr)) != -1) {
fos.write(arr, 0, len); // write(arr, off, count)
}
fis.close();
fos.close();这里就是把一个文件分好几段来读:
len 代表本次读到的有效字节个数,而下面 write 方法中有三个变量,第一个 arr 是刚才读到的那一段内容,比如我规定了 byte 数组大小是 4,读到了 abcd ,然后在 write 中,arr 的内容就是 abcd ,之后第二个参数 off 是表从第几个开始写入,如果是 0,那就代表从 a 开始往后拷贝,如果是 1,那就是从 b 开始往后拷贝,然后第三个参数表示拷贝多少个过去,如果是按照示例代码里的意思是,把这一个 arr 内的全部都拷贝过去,如果改成了 3 ,那就拷贝 3 个过去,这里注意别越界了。
注意一点:那个 byte[] 的大小,里面一般用 1024 的整数倍
这个其实实现就是上面的用数组一段段搬运来实现的,底部默认 byte 数组大小是 8192。每一个 BufferedStream 都需要对 InputStream 和 OutputStream 进行包装。同时,在关流的时候,只需要关 BufferedStream 就可以了。Buffer 之所以效率会比较高,还有一个原因是,buffer 的操作是在内存上处理的,它先把读到的放在 Input Buffer 中,然后把这些内容放进 Output Buffer 中,最后集中写进硬盘,这个过程会减少单次写入的次数。Java在设计这个的时候,应用了装饰设计者模式。
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("xxx.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.txt"));
int b;
while ((b = bis.read()) != -1) {
bos.write(b); // 这里一次写在 output buffer 里的是一个 byte 数组
}这个比较上面小数组的话,如果都是定义了一个8192大小的 byte[] 的话,那么小数组会稍微快一点点,因为小数组的话前后都是操作的同一个数组。
Close:
这个 Buffer 在每一次写满 8192 的时候,都会自动写到对应的文件里,但是大多数时候都会存在文件的大小不是 8192 的倍数。那么这种情况下,close 的调用会把 byte 数组里剩下那一些给写过去,然后再关闭流。
Flush:
调用一次 flush 方法,程序就会把那个 byte 数组里的内容给写到硬盘上,但是不会关闭流。Flush 方法多用在需要实时刷新数据的地方,比如聊天软件中。
在读的时候,由于一个中文是两个 byte 构成,小数组所以可能会出现一个字没读齐的情况,就算把 byte 数组写成 2 的倍数,也不可能说一串中文字符串里没有标点符号。所以再读中文的时候,会遇到很多麻烦,后续用字符流解决。
而在往外写字符串的时候,无论是中文还是英文都需要先转成 byte 数组,然后写过去,包括换行符 "\r\n" 也是需要写调用 .getBytes() 的方法。
1.6 版本及之前的:
public static void main(String[] args) throws IOException {
FileInputStream fis = null; // 此处两个 null 是为了其能在局部变量中进行使用
FIleOutputStream fos = null;
try {
fis = new FileInputStream("xxx.txt"); // 可能出现异常的地方
fos = new FileOutputStream("yyy.txt");
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
} finally { // 当抛出异常之后,进行关流的操作
try {
if (fis != null) { // 因为之前赋的是 null,如果发生异常,没有产生实例对象
fis.close(); // 那 .close() 可能会抛出空指针异常
}
} finally { // 进行嵌套,来尽可能的把两个都进行关闭,Finally嵌套写法。
if (fos != null) {
fos.close();
}
}
}
}1.7开始的新的处理方式:
public static void main(String[] args) throws IOException {
try (
FileInputStream fis = new FileInputStream("xxx.txt");
FileOutputStream fos = new FileOutputStream("yyy.txt");
Myclose mc = new Myclose();
) {
int b;
while ((b = fis.read() != -1) {
fos.wirte(b);
}
}
}
class Myclose implements AutpCloseable {
public void close() {
System.out.println("我关了");
}
}在 1.7 开始,可以通过 try 之后用小括号扩起来创建流通道的这个步骤,之后后面就不用考虑流关不关闭的问题了,因为 Java 会自动处理这个东西。因为 Input/OutputStream 中实现了 AutoCloseable 的接口,可以做到自动关闭,所以再上述代码中,Myclose 的实例,也会在程序结束的时候自动调用 close() 方法,然后输出 “我关了”
在读到一个图片之后,把每一个字节都进行一些列操作,课程中用的是异或 (XOR) 操作,一个数异或两次等于本身,所以在读取加密的图片之后,直接再异或之前的那个数,图片就等于被解密出来了。
一个接口,自己可以规定怎么比较两个对象的规则,一般通过一个类实现这个接口后,把这个类的实例化对象传入作为参数,一般在创造集合的时候可以使用,比如 TreeSet
举例用法:
class ComapreByLen implements Comparator<String> {
@Override
public int compare(String s1, String s2) {
int num = s1.length() - s2.length(); // 先主要比较长度
return num == 0 ? s1.compareTo(s2) : num ; // 后比较内容
}
}
class Myclass {
public static void main(String[] args) {
TreeSet<String> ts = new TreeSet<>(new CompareByLen());
// 传进的 String 就会按照上面定义的规则进行排序
}
}import static java.until.Arrays.sort;public static void print(int ... arr) {
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}这个主要是用在不知道定义多少个参数的时候,而且要放在最后一个参数来使用。
举例:Arrays里有一个方法是这么写的
static<T> List<T> asList(T ... a)方法和 Arrays 工具类的使用方法一样
排序:
public static <T> void sort(List<T> list)二分查找法:
public static <T> int binarySearch(List<?> list, T key)找最大值:
public static <T> T max(Collections<?> coll)反转:
public static void reverse(List<?> list)随机打乱:
public static void shuffle(List<?> list)